Java Stream.md
花门楼前见秋草,岂能贫贱相看老。
Java Stream
1. 什么是 Stream
Stream支持顺序和并行聚合操作的元素序列。以下示例说明了使用Stream和IntStream的聚合操作:
int sum = widgets.stream()
.filter(w -> w.getColor() == RED)
.mapToInt(w -> w.getWeight())
.sum();
在本例中,小部件是一个集合<小部件>。我们通过Collection.stream()创建一个Widget对象流,对其进行过滤以生成一个仅包含红色小部件的流,然后将其转换为表示每个红色小部件权重的int值流。然后将该流相加以产生总重量。
除了Stream,它是一个对象引用流,还有IntStream、LongStream和DoubleStream的原始专门化,所有这些都被称为“流”,并符合此处描述的特性和限制。
为了执行计算,流操作被组成一个流管道。流管道由一个源(可能是数组、集合、生成器函数、I/O通道等)、零个或多个中间操作(将流转换为另一个流,如filter(Predicate))和一个终端操作(产生结果或副作用,如count()或forEach(Consumer))组成。溪流是懒惰的;仅当终端操作启动时才执行对源数据的计算,并且仅根据需要消耗源元素。
流实现在优化结果的计算方面被允许有很大的自由度。例如,如果流实现能够证明它不会影响计算结果,那么它可以自由地取消流管道中的操作(或整个阶段),从而取消行为参数的调用。这意味着行为参数的副作用可能并不总是被执行,也不应该被依赖,除非另有规定(例如通过终端操作forEach和forEachOrdered)。
集合和流虽然有一些表面上的相似之处,但有不同的目标。藏品主要涉及对其元素的有效管理和访问。相比之下,流不提供直接访问或操作其元素的手段,而是关心声明性地描述其源以及将在该源上聚合执行的计算操作。但是,如果提供的流操作没有提供所需的功能,则迭代器()和spliterator()操作可以用于执行受控遍历。
流管道,就像上面的“小部件”示例一样,可以看作是对流源的查询。除非源明确设计用于并发修改(如ConcurrentHashMap),否则在查询流源时修改流源可能会导致不可预测或错误的行为。
流应该只操作一次(调用中间或终端流操作)。例如,这排除了“分叉”流,即同一个源提供两个或多个管道,或同一流的多个遍历。如果流实现检测到流正在被重用,它可能会抛出IllegalStateException。然而,由于一些流操作可能返回它们的接收器而不是新的流对象,因此可能不可能在所有情况下都检测到重用。
流有一个close()方法并实现了AutoCloseable。在流关闭后对其进行操作将引发IllegalStateException。大多数流实例在使用后实际上不需要关闭,因为它们由集合、数组或生成函数支持,不需要特殊的资源管理。通常,只有源为IO通道的流,例如由Files.lines(Path)返回的流,才需要关闭。如果流确实需要关闭,则必须在try-with-resources语句或类似的控制结构中将其作为资源打开,以确保在操作完成后立即关闭。
流管道可以按顺序执行,也可以并行执行。此执行模式是流的一个属性。流是通过顺序执行或并行执行的初始选择创建的。(例如,Collection.stream()创建一个顺序流,Collection.sparallelStream()创建并行流。)这种执行模式的选择可以通过sequencial()或parallel()方法进行修改,也可以通过isParallel(()方法查询。
Stream是数据渠道,用于操作数据源所生成的元素序列,它可以实现对集合(Collection)的复杂操作,例如查找、替换、过滤和映射数据等操作。
我们这里说的Stream不同于java的输入输出流。另外,Collection 是一种静态的数据结构,存储在内存中,而Stream是用于计算的,通过CPU实现计算。注意不要混淆。
- 惰性求值:如果没有终结操作,流的中间操作是不会执行的
- 流是一次性的:一个流对象经过一个终结操作后,这个流就不能再使用了
- 不会影响原数据:正常情况下流的操作不会影响原数据
Tips:
Stream自己不会存储数据;Stream不会改变源对象,而是返回一个新的持有结果的Stream(不可变性);Stream操作是延迟执行的(这一点将在后面介绍)。
以下代码:
public Long[] getNewUserByMonth(String month) {
Long[] result = new Long[30];
List<MonthNewUserDto> newUserDtos = baseMapper.getNewUserByMonth(month);
newUserDtos.forEach(System.out::println);
newUserDtos.stream().map(item ->
result[Integer.parseInt(item.getDaystr().substring(item.getDaystr().length() - 2))] = item.getCounts());
System.out.println("result = " + Arrays.toString(result));
return result;
}
输出:
MonthNewUserDto(daystr=2022-12-01, counts=47)
MonthNewUserDto(daystr=2022-12-02, counts=46)
MonthNewUserDto(daystr=2022-12-03, counts=25)
MonthNewUserDto(daystr=2022-12-04, counts=47)
MonthNewUserDto(daystr=2022-12-05, counts=29)
MonthNewUserDto(daystr=2022-12-06, counts=38)
MonthNewUserDto(daystr=2022-12-07, counts=37)
MonthNewUserDto(daystr=2022-12-08, counts=25)
MonthNewUserDto(daystr=2022-12-09, counts=24)
result = [null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null]
可以发现result并没有被更新,只要流没有终止操作,那么流中间的步骤都不会执行
2. 为什么使用 Stream API
我们在实际开发中,项目中的很多数据都来源于关系型数据库(例如 MySQL、Oracle 数据库),我们使用SQL的条件语句就可以实现对数据的筛选、过滤等等操作;
但也有很多数据来源于非关系型数据库(Redis、MongoDB等),想要处理这些数据,往往需要在 Java 层面去处理。
使用Stream API对集合中的数据进行操作,就类似于 SQL 执行的数据库查询。也可以使用Stream API来执行并行操作。简单来说,Stream API提供了一种高效且易于使用的处理数据的方式。
3. 流式操作的执行流程
流式操作通常分为以下 3 个步骤:
-
创建
Stream对象:通过一个数据源(例如集合、数组),获取一个流; - 中间操作:一个中间的链式操作,对数据源的数据进行处理(例如过滤、排序等),直到执行终止操作才执行;
- 终止操作:一旦执行终止操作,就执行中间的链式操作,并产生结果。
下图展示了Stream的执行流程:
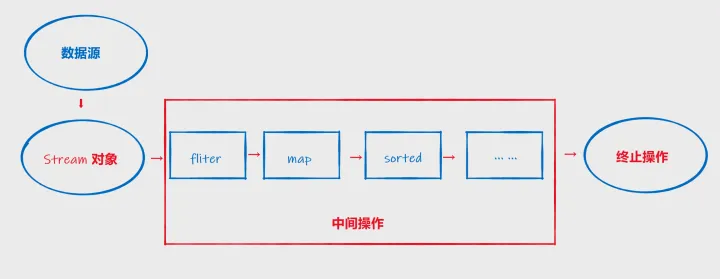
接下来我们就按照这 3 个步骤的顺序来展开学习Stream API。
4. Stream 对象的创建
有 4 种方式来创建Stream对象。
4.1 通过集合创建 Stream
Java 8 的java.util.Collection 接口被扩展,提供了两个获取流的默认方法:
-
default Stream<E> stream():返回一个串行流(顺序流); -
default Stream<E> parallelStream():返回一个并行流。
实例如下:
// 创建一个集合,并添加几个元素
List<String> stringList = new ArrayList<>();
stringList.add("hello");
stringList.add("world");
stringList.add("java");
// 通过集合获取串行 stream 对象
Stream<String> stream = stringList.stream();
// 通过集合获取并行 stream 对象
Stream<String> personStream = stringList.parallelStream();
串行流并行流的区别是:串行流从集合中取数据是按照集合的顺序的;而并行流是并行操作的,获取到的数据是无序的。
Map 获取流
@Test
public void test7() throws Exception {
HashMap<Integer, String> map = new HashMap<>() ;
// map 没有直接创建流的方法
// map.stream()
// 转为 set 集合
Set<Map.Entry<Integer, String>> entrySet = map.entrySet();
Stream<Map.Entry<Integer, String>> stream = entrySet.stream();
stream.forEach(System.out::println);
}
4.2 通过数组创建 Stream
Java 8 中的java.util.Arrays的静态方法stream()可以获取数组流:
-
static <T> Stream<T> stream(T[] array):返回一个数组流。
此外,stream()还有几个重载方法,能够处理对应的基本数据类型的数组:
-
public static IntStream stream(int[] array):返回以指定数组作为其源的连续IntStream; -
public static LongStream stream(long[] array):返回以指定数组作为其源的连续LongStream; -
public static DoubleStream stream(double[] array):返回以指定数组作为其源的连续DoubleStream。
实例如下:
import java.util.Arrays;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class StreamDemo1 {
public static void main(String[] args) {
// 初始化一个整型数组
int[] arr = new int[]{1,2,3};
// 通过整型数组,获取整形的 stream 对象
IntStream stream1 = Arrays.stream(arr);
// 通过字符串类型的数组,获取泛型类型为 String 的 stream 对象
String[] stringArr = new String[]{"Hello", "imooc"};
Stream<String> stream2 = Arrays.stream(stringArr);
}
}
获取连续数字组成的流:
@Test
public void test9() throws Exception {
// 获取 0 - 9 之间的整数流
IntStream stream = IntStream.range(0, 10);
stream.forEach(System.out::println);
// 可以进行装箱操作获得 Integer 类型流
Stream<Integer> boxed = stream.boxed();
boxed.forEach(System.out::println);
}
4.3 通过 Stream 的 of()方法
可以通过Stream类下的of()方法来创建 Stream 对象,实例如下:
import java.util.stream.Stream;
public class StreamDemo1 {
public static void main(String[] args) {
// 通过 Stream 类下的 of() 方法,创建 stream 对象、
Stream<Integer> stream = Stream.of(1, 2, 3);
}
}
4.4 创建无限流
可以使用Stream类下的静态方法iterate()以及generate()创建无限流:
-
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f):遍历; -
public static<T> Stream<T> generate(Supplier<T> s):生成。
创建无限流的这种方式实际使用较少,大家了解一下即可。
5. Stream 的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理。在终止操作时会一次性全部处理这些中间操作,称为惰性求值。下面,我们来学习一下常用的中间操作方法。
5.1 筛选与切片
关于筛选和切片中间操作,有下面几个常用方法:
-
filter(Predicate p):接收Lambda,从流中清除某些元素; -
distinct():筛选,通过流生成元素的hashCode和equals()方法去除重复元素; -
limit(long maxSize):截断流,使其元素不超过给定数量; -
skip(long n):跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit(n)互补。
我们先来看一个过滤集合元素的实例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class StreamDemo2 {
static class Person {
private String name;
private int age;
public Person() { }
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* 创建一个 Person 的集合
* @return List
*/
public static List<Person> createPeople() {
ArrayList<Person> people = new ArrayList<>();
Person person1 = new Person("小明", 15);
Person person2 = new Person("小芳", 20);
Person person3 = new Person("小李", 18);
Person person4 = new Person("小付", 23);
Person person5 = new Person("大飞", 22);
people.add(person1);
people.add(person2);
people.add(person3);
people.add(person4);
people.add(person5);
return people;
}
public static void main(String[] args) {
List<Person> people = createPeople();
// 创建 Stream 对象
Stream<Person> stream = people.stream();
// 过滤年龄大于 20 的 person
Stream<Person> personStream = stream.filter(person -> person.getAge() >= 20);
// 触发终止操作才能执行中间操作,遍历列表中元素并打印
personStream.forEach(System.out::println);
}
}
运行结果:
Person{name='小芳', age=20}
Person{name='小付', age=23}
Person{name='大飞', age=22}
实例中,有一个静态内部类Person以及一个创建Person的集合的静态方法createPeople(),在主方法中,我们先调用该静态方法获取到一个Person列表,然后创建了Stream对象,再执行中间操作(即调用fliter()方法),这个方法的参数类型是一个断言型的函数式接口,接口下的抽象方法test()要求返回boolean结果,因此我们使用Lambda表达式,Lambda体为person.getAge() >= 20,其返回值就是一个布尔型结果,这样就实现了对年龄大于等于 20 的person对象的过滤。
由于必须触发终止操作才能执行中间操作,我们又调用了forEach(System.out::println),在这里记住它作用是遍历该列表并打印每一个元素即可,我们下面将会讲解。另外,filter()等这些由于中间操作返回类型为 Stream,所以支持链式操作,我们可以将主方法中最后两行代码合并成一行:
stream.filter(person -> person.getAge() >= 20).forEach(System.out::println);
我们再来看一个截断流的使用实例:
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class StreamDemo3 {
static class Person {
private String name;
private int age;
public Person() { }
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
/**
* 创建一个 Person 的集合
* @return List
*/
public static List<Person> createPeople() {
ArrayList<Person> people = new ArrayList<>();
Person person1 = new Person("小明", 15);
Person person2 = new Person("小芳", 20);
Person person3 = new Person("小李", 18);
Person person4 = new Person("小付", 23);
Person person5 = new Person("大飞", 22);
people.add(person1);
people.add(person2);
people.add(person3);
people.add(person4);
people.add(person5);
return people;
}
public static void main(String[] args) {
List<Person> people = createPeople();
// 创建 Stream 对象
Stream<Person> stream = people.stream();
// 截断流,并调用终止操作打印集合中元素
stream.limit(2).forEach(System.out::println);
}
}
运行结果:
Person{name='小明', age=15}
Person{name='小芳', age=20}
根据运行结果显示,我们只打印了集合中的前两条数据。
跳过前 2 条数据的代码实例如下:
// 非完整代码
public static void main(String[] args) {
List<Person> people = createPeople();
// 创建 Stream 对象
Stream<Person> stream = people.stream();
// 跳过前两个元素,并调用终止操作打印集合中元素
stream.skip(2).forEach(System.out::println);
}
运行结果:
Person{name='小李', age=18}
Person{name='小付', age=23}
Person{name='大飞', age=22}
distinct()方法会根据equals()和hashCode()方法筛选重复数据,我们在Person类内部重写这两个方法,并且在createPerson()方法中,添加几个重复的数据 ,实例如下:
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.stream.Stream;
public class StreamDemo4 {
static class Person {
private String name;
private int age;
public Person() { }
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
/**
* 创建一个 Person 的集合
* @return List
*/
public static List<Person> createPeople() {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("小明", 15));
people.add(new Person("小芳", 20));
people.add(new Person("小李", 18));
people.add(new Person("小付", 23));
people.add(new Person("大飞", 22));
return people;
}
public static void main(String[] args) {
List<Person> people = createPeople();
// 创建 Stream 对象
Stream<Person> stream = people.stream();
System.out.println("去重前,集合中元素有:");
stream.forEach(System.out::println);
System.out.println("去重后,集合中元素有:");
// 创建一个新流
Stream<Person> stream1 = people.stream();
// 截断流,并调用终止操作打印集合中元素
stream1.distinct().forEach(System.out::println);
}
}
运行结果:
去重前,集合中元素有:
Person{name='小明', age=15}
Person{name='小芳', age=20}
Person{name='小李', age=18}
Person{name='小付', age=23}
Person{name='大飞', age=22}
去重后,集合中元素有:
Person{name='小明', age=15}
Person{name='小芳', age=20}
Person{name='小李', age=18}
Person{name='小付', age=23}
Person{name='大飞', age=22}
5.2 映射
关于映射中间操作,有下面几个常用方法:
-
map(Function f):接收一个方法作为参数,该方法会被应用到每个元素上,并将其映射成一个新的元素; -
mapToDouble(ToDoubleFunction f):接收一个方法作为参数,该方法会被应用到每个元素上,产生一个新的DoubleStream; -
mapToLong(ToLongFunction f):接收一个方法作为参数,该方法会被应用到每个元素上,产生一个新的LongStream; -
flatMap(Function f):接收一个方法作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
请查看如下实例:
import java.util.Arrays;
import java.util.List;
public class StreamDemo5 {
public static void main(String[] args) {
// 创建一个包含小写字母元素的字符串列表
List<String> stringList = Arrays.asList("php", "js", "python", "java");
// 调用 map() 方法,将 String 下的 toUpperCase() 方法作为参数,这个方法会被应用到每个元素上,映射成一个新元素,最后打印映射后的元素
stringList.stream().map(String::toUpperCase).forEach(System.out::println);
}
}
运行结果:
PHP
JS
PYTHON
JAVA
可参考下图,理解映射的过程:
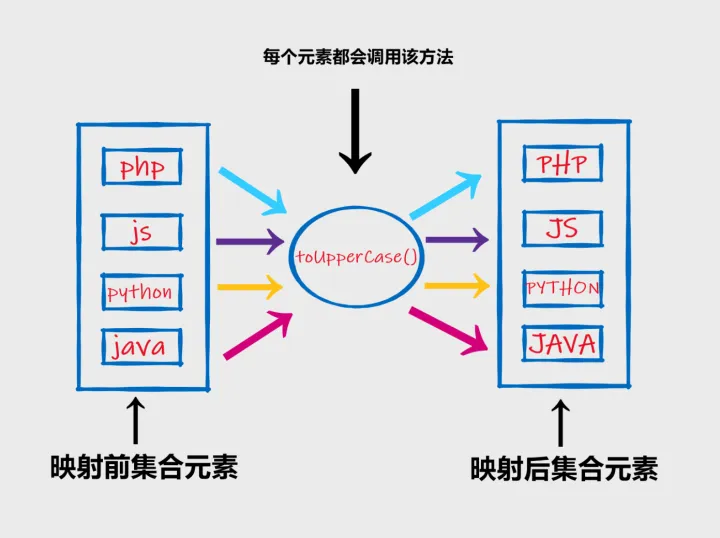
flatMap 可以映射为新的流以执行后续操作,并不常用。
@Test
public void test14() throws Exception {
Stream<Integer> boxed = IntStream.range(0, 9).boxed();
Set<String> set = boxed.flatMap(integer -> Stream.of("转换为字符:"+ integer)).collect(Collectors.toSet());
set.forEach(System.out::println);
}
转换为字符:0
转换为字符:1
转换为字符:2
转换为字符:3
转换为字符:4
转换为字符:5
转换为字符:6
转换为字符:7
转换为字符:8
5.3 排序
关于排序中间操作,有下面几个常用方法:
-
sorted():产生一个新流,其中按照自然顺序排序; -
sorted(Comparator com):产生一个新流,其中按照比较器顺序排序。
请查看如下实例:
import java.util.Arrays;
import java.util.List;
public class StreamDemo6 {
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(10, 12, 9, 8, 20, 1);
// 调用 sorted() 方法自然排序,并打印每个元素
integers.stream().sorted().forEach(System.out::println);
}
}
运行结果:
1
8
9
10
12
20
上面实例中,我们调用sorted()方法对集合元素进行了从小到大的自然排序,那么如果想要实现从大到小排序,任何实现呢?此时就要用到sorted(Comparator com)方法定制排序,查看如下实例:
import java.util.Arrays;
import java.util.List;
public class StreamDemo6 {
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(10, 12, 9, 8, 20, 1);
// 定制排序
integers.stream().sorted(
(i1, i2) -> -Integer.compare(i1, i2)
).forEach(System.out::println);
}
}
运行结果:
20
12
10
9
8
1
实例中,sorted()方法接收的参数是一个函数式接口Comparator,因此使用Lambda表达式创建函数式接口实例即可,Lambda体调用整型的比较方法,对返回的整型值做一个取反即可。
6. Stream 的终止操作
执行终止操作会从流的流水线上生成结果,其结果可以是任何不是流的值,例如List、String、void。
在上面实例中,我们一直在使用forEach()方法来执行流的终止操作,下面我们看看还有哪些其他终止操作。
6.1 匹配与查找
关于匹配与查找的终止操作,有下面几个常用方法:
-
allMatch(Predicate p):检查是否匹配所有元素; -
anyMatch(Predicate p):检查是否至少匹配一个元素; -
noneMatch(Predicate p):检查是否没有匹配所有元素; -
findFirst():返回第一个元素; -
findAny():返回当前流中的任意元素; -
count():返回流中元素总数; -
max(Comparator c):返回流中最大值; -
min(Comparator c):返回流中最小值; -
forEach(Consumer c):内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代;相反Stream API使用内部迭代)。
如下实例,演示了几个匹配元素相关方法的使用:
import java.util.Arrays;
import java.util.List;
public class StreamDemo7 {
public static void main(String[] args) {
// 创建一个整型列表
List<Integer> integers = Arrays.asList(10, 12, 9, 8, 20, 1);
// 使用 allMatch(Predicate p) 检查是否匹配所有元素,如果匹配,则返回 true;否则返回 false
boolean b1 = integers.stream().allMatch(integer -> integer > 0);
if (b1) {
System.out.println(integers + "列表中所有的元素都大于 0");
} else {
System.out.println(integers + "列表中不是所有的元素都大于 0");
}
// 使用 anyMatch(Predicate p) 检查是否至少匹配一个元素
boolean b2 = integers.stream().anyMatch(integer -> integer >= 20);
if (b2) {
System.out.println(integers + "列表中至少存在一个的元素都大于等于 20");
} else {
System.out.println(integers + "列表中不存在任何一个大于等于 20 的元素");
}
// 使用 noneMath(Predicate p) 检查是否没有匹配所有元素
boolean b3 = integers.stream().noneMatch(integer -> integer > 100);
if (b3) {
System.out.println(integers + "列表中不存在大于 100 的元素");
} else {
System.out.println(integers + "列表中存在大于 100 的元素");
}
}
}
运行结果:
[10, 12, 9, 8, 20, 1] 列表中所有的元素都大于 0
[10, 12, 9, 8, 20, 1] 列表中至少存在一个的元素都大于等于 20
[10, 12, 9, 8, 20, 1] 列表中不存在大于 100 的元素
查找元素的相关方法使用实例如下:
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
public class StreamDemo8 {
public static void main(String[] args) {
// 创建一个整型列表
List<Integer> integers = Arrays.asList(10, 12, 9, 8, 20, 1);
// 使用 findFirst() 获取当前流中的第一个元素
Optional<Integer> first = integers.stream().findFirst();
System.out.println(integers + "列表中第一个元素为:" + first);
// 使用 findAny() 获取当前流中的任意元素
Optional<Integer> any = integers.stream().findAny();
System.out.println("列表中任意元素:" + any);
// 使用 count() 获取当前流中元素总数
long count = integers.stream().count();
System.out.println(integers + "列表中元素总数为" + count);
// 使用 max(Comparator c) 获取流中最大值
Optional<Integer> max = integers.stream().max(Integer::compare);
System.out.println(integers + "列表中最大值为" + max);
// 使用 min(Comparator c) 获取流中最小值
Optional<Integer> min = integers.stream().min(Integer::compare);
System.out.println(integers + "列表中最小值为" + min);
}
}
运行结果:
[10, 12, 9, 8, 20, 1] 列表中第一个元素为:Optional[10]
列表中任意元素:Optional[10]
[10, 12, 9, 8, 20, 1] 列表中元素总数为 6
[10, 12, 9, 8, 20, 1] 列表中最大值为 Optional[20]
[10, 12, 9, 8, 20, 1] 列表中最小值为 Optional[1]
实例中,我们观察到findFirst()、findAny()、max()等方法的返回值类型为Optional类型,关于这个Optional类,我们将在下一小节具体介绍。
6.2 Reduce 归约
关于归约的终止操作,有下面几个常用方法:
-
可以将流中的元素反复结合起来,得到一个值。返回
Optional<T>,当流中没有元素时需要做非空判断;accumulator: 累加操作,接收 2 为操作数 。Optional<T> reduce(BinaryOperator<T> accumulator);eg:
@Test public void test16() throws Exception { Optional<Integer> optional = IntStream.range(0, 9).boxed().reduce(Integer::sum); System.out.println(optional.get()); }输出:
36@Test public void test16() throws Exception { Optional<Integer> optional = new ArrayList<Integer>().stream().reduce(Integer::sum); System.out.println(optional.get()); }输出:
java.util.NoSuchElementException: No value present -
identity:accumulator操作的初始值,流为空时将作为默认返回。T reduce(T identity, BinaryOperator<T> accumulator);@Test public void test17() throws Exception { Integer reduce = new ArrayList<Integer>().stream().reduce(0, Integer::sum); System.out.println("reduce = " + reduce); }输出:
reduce = 0 -
combiner:当使用parallel并行流时该操作才会执行,用于统计各个线程的执行结果。因为串行流只有一个结果,没有统计的必要。<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);`eg: 虽然在 combiner 操作中声明了抛出异常,由于是串行流,只有一条线程去执行,并不会执行 combiner 操作。
public void test18() throws Exception { Integer reduce = IntStream.range(0, 9).boxed().reduce( 0, Integer::sum, (v1, v2) -> { throw new RuntimeException("combiner"); }); System.out.println("reduce = " + reduce); }输出:
reduce = 36采用并行流的方式执行:此时需要注意
identity可能被多次累加。@Test public void test19() throws Exception { Integer reduce = IntStream.range(0, 9).boxed().parallel().reduce(0, (v1, v2) -> { System.out.printf("accumulator: %s: v1 = %s, v2 = %s \n", Thread.currentThread().getName(), v1, v2); return v1 + v2; }, (v1, v2) -> { System.out.printf("combiner: %s: v1 = %s, v2 = %s \n", Thread.currentThread().getName(), v1, v2); return v1 + v2; }); System.out.println("reduce = " + reduce); }输出:
accumulator: main: v1 = 0, v2 = 5 accumulator: main: v1 = 0, v2 = 4 combiner: main: v1 = 4, v2 = 5 accumulator: main: v1 = 0, v2 = 7 accumulator: main: v1 = 0, v2 = 8 combiner: main: v1 = 7, v2 = 8 accumulator: ForkJoinPool.commonPool-worker-2: v1 = 0, v2 = 1 accumulator: ForkJoinPool.commonPool-worker-3: v1 = 0, v2 = 6 accumulator: main: v1 = 0, v2 = 0 combiner: main: v1 = 0, v2 = 1 accumulator: ForkJoinPool.commonPool-worker-4: v1 = 0, v2 = 3 accumulator: ForkJoinPool.commonPool-worker-1: v1 = 0, v2 = 2 combiner: ForkJoinPool.commonPool-worker-3: v1 = 6, v2 = 15 combiner: ForkJoinPool.commonPool-worker-3: v1 = 9, v2 = 21 combiner: ForkJoinPool.commonPool-worker-1: v1 = 2, v2 = 3 combiner: ForkJoinPool.commonPool-worker-1: v1 = 1, v2 = 5 combiner: ForkJoinPool.commonPool-worker-1: v1 = 6, v2 = 30 reduce = 36
6.3 收集
collect(Collector c):将流转换为其他形式。接收一个Collector接口的实现,用于给Stream中元素做汇总的方法。
实例如下:
import java.util.Arrays;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
public class StreamDemo10 {
public static void main(String[] args) {
// 创建一个整型列表
List<Integer> integers = Arrays.asList(10, 12, 9, 8, 20, 1, 10);
Set<Integer> collect = integers.stream().collect(Collectors.toSet());
System.out.println(collect);
}
}
运行结果:
[1, 20, 8, 9, 10, 12]
Collector 接口中的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。java.util.stream.Collectors 类提供了很多静态方法,可以方便地创建常用收集器实例,常用静态方法如下:
-
static List<T> toList():把流中元素收集到List; -
static Set<T> toSet():把流中元素收集到Set; -
static Collection<T> toCollection():把流中元素收集到创建的集合。
案例
计算单词长度
需求说明
假设有字符串流,利用每个字符串对象有方法length()————计算并返回单词长度。我们想创建自定义Collector,实现reduce操作,计算流中所有单词的长度之和。
使用 Collector.of() 方法
为了创建自定义Collector,需要实现Collector接口。现在,我们不使用传统方法,而是使用Collector.of()静态方法创建自定义Collector。
不仅是为了更精简和增强可读性,还因为这种方法可以忽略部分不必要的实现。实际上,Collector接口仅需要三个必须部分
- 提供者(supplier)
- 累加器(accumulator)
- 合并器(combiner)。
结果容器提供者(supplier)
实现Collector,必须提供结果容器,即累加值存储的地方。下面代码提供了结果容器:
() -> new int[1]
你可能会想,为什么是 new int[1],而不是int变量作为初始化值。原因是Collector接口需要结果容器能够以可变的方式进行更新。
累加元素(accumulator)
接下来,我们需要创建函数实现增加元素至结果容器。在我们的示例中,即单词的长度增加至结果容器:
(result, item) -> result[0] += item.length()
该函数是Consumer类型,其不返回任何值,仅以可变的方式更新结果容器————即数组中的第一个元素。
合并器(combiner)
在reduction序列操作中,提供者(supplier) 和 累加器(accumulator) 已经足够了,但为了能够实现并行操作,我们需要实现一个合并器。合并器(combiner)是定义两个结果如何合并的函数。 在并行环境下,流被分为多个部分,每个部分被并行累加。当所有部分都完成时,结果需要使用合并器函数进行合并。下面请看我们的实现代码:
(result1, result2) -> {
result1[0] += result2[0];
return result1;
}
最小的自定义Collector
现在我们已经所有必要组件,整合在一起就是我们的Collector:
wordStream.collect(Collector.of(
()-> new int[1],
(result, item) -> result[0] += item.length(),
(result1, result2) -> {
result1[0] += result2[0];
return result1;
}
));
上面方案有个小问题,其直接返回结果容器即int[]类型。实际我们需要的字符串长度,不是结果容器。
最后一个转换
我们可以很容易实现,增加一个函数,其映射结果容器至我们需要的类型。这里我们仅仅需要数组的第一个元素:
total -> total[0]
最后完整代码为:
private List<String> wordList = Arrays.asList("tommy", "is", "a", "java", "developer");
@Test
public void wordCountTest() {
Stream<String> wordStream = wordList.stream();
int wordCnt = wordStream.collect(Collector.of(
()-> new int[1],
(result, item) -> result[0] += item.length(),
(result1, result2) -> {
result1[0] += result2[0];
return result1;
},
total -> total[0]
));
System.out.println("wordCnt = " + wordCnt);
}
如果把我们自定义的Collector赋值给变量,则代码可以简化为:
int wordCount = wordStream.collect(totalWordCountCollector);
优化参数
最后,我们看下优化参数。即自定义Collector支持不同类型的优化参数。
使用Collector.of() 可以在参数最后增加 Characteristics 作为可变参数:
Collector.of(
// supplier,
// accumulator,
// combiner,
// finisher,
Collector.Characteristics.CONCURRENT,
Collector.Characteristics.IDENTITY_FINISH,
// ...
);
有三种 Characteristics 可以使用:
- CONCURRENT — 指明结果容器可以被多个并发累加器使用
- IDENTITY_FINISH — 指明结束函数是恒等函数且可以被忽略
- UNORDERED — 指明collector不依赖元素顺序
单词的频次统计
单词的频次统计是学习大数据中的一个相当经典的案例。像使用 MapReduce、Scala、Spark、Hive等技术都可以完成,相应的操作。在 Java8 中,其新增的特性Stream流,也可以很简单的完成单词频次统计的案例。 下面上一段代码:
@Test
public void test() {
List<String> list = Arrays.asList("hello","hadoop","hive","hadoop","hadoop","hello");
list.stream().collect(Collectors.groupingBy((x)->x)).values().stream().map((x)->{Map map=new HashMap<>();map.put(x.get(0), x.size());return map;}).forEach(System.out::println);
}
这里是输出结果: {hive=1} {hadoop=3} {hello=2} 这样,就通过一句话就完成了这个单词频次统计的小案例。看这种代码风格是不是很像[Scala]语言。 下面,我来把上面的代码做一下拆分:
@Test
public void test() {
List<String> list = Arrays.asList("hello","hadoop","hive","hadoop","hadoop","hello");
Map<String, List<String>> collect = list.stream().collect(Collectors.groupingBy((x)->x));
Stream<Map<String,Integer>> stream = collect.values().stream().map((x)->{Map<String, Integer> map=new HashMap<>();map.put(x.get(0), x.size());return map;});
stream.forEach(System.out::println);
}
更加精简的写法:
List<String> words = Arrays.asList("hello", "hadoop", "hive", "hadoop", "hadoop", "hello");
System.out.println(words.parallelStream().collect(Collectors.groupingBy(it -> it, Collectors.counting())));
或:
List<String> words = Arrays.asList("hello", "hadoop", "hive", "hadoop", "hadoop", "hello");
System.out.println(words.parallelStream().map(it -> new Tuple<>(it, 1)).collect(Collectors.groupingBy(Tuple::getIt1,
Collectors.summingInt(Tuple::getIt2))));
@Data
@AllArgsConstructor
class Tuple<T, E> {
private T it1;
private E it2;
}
Python中的写法:
words = ["hello", "hadoop", "hive", "hadoop", "hadoop", "hello"]
print({word: words.count(word) for word in words})
7. 小结
通过本小节的学习,我们知道了Stream不同于java.io下的输入输出流,它主要用于处理数据。Stream API可用于处理非关系型数据库中的数据;想要使用流式操作,就要知道创建Stream对象的几种方式;流式操作可分为创建Stream对象、中间操作和终止操作三个步骤。多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理。执行终止操作会从流的流水线上生成结果,其结果可以是任何不是流的值。
版权声明:如无特别声明,本站收集的文章归 HuaJi66/Others 所有。 如有侵权,请联系删除。
联系邮箱: GenshinTimeStamp@outlook.com
本文标题:《 Java Stream.md 》

